MoneyPrinterPlus可以使用大模型自动生成短视频,我们可以借助Azure提供的语音服务来实现语音合成和语音识别的功能。
Azure的语音服务应该是我用过的效果最好的服务了,微软还得是微软。
很多小伙伴可能不知道应该如何配置,这里给大家提供一个详细的Azure语音服务的配置教程。
项目已开源,代码地址:https://github.com/ddean2009/MoneyPrinterPlus
Azure的具体配置
因为Azure的注册需要用到VISA,所以阻止了很多想要进一步探索的小伙伴。
其实,MoneyPrinterPlus也是支持国内的云厂商,比如阿里云和腾讯云。所以,如果注册Azure有困难的小伙伴,可以参考我的另外两篇使用阿里云和腾讯云的介绍文章。
这里Azure为例,来讲解如何进行Azure语音的配置。
获取Azure的Speech Key和Service Region
首先我们到Azure�的官网上去注册一个账号,怎么注册这里就不讲了,反正很简单,注册成功还可以免费使用一年的微软云服务,非常的棒。
有了账号,并且登录账号之后,在搜索框输入语音服务:
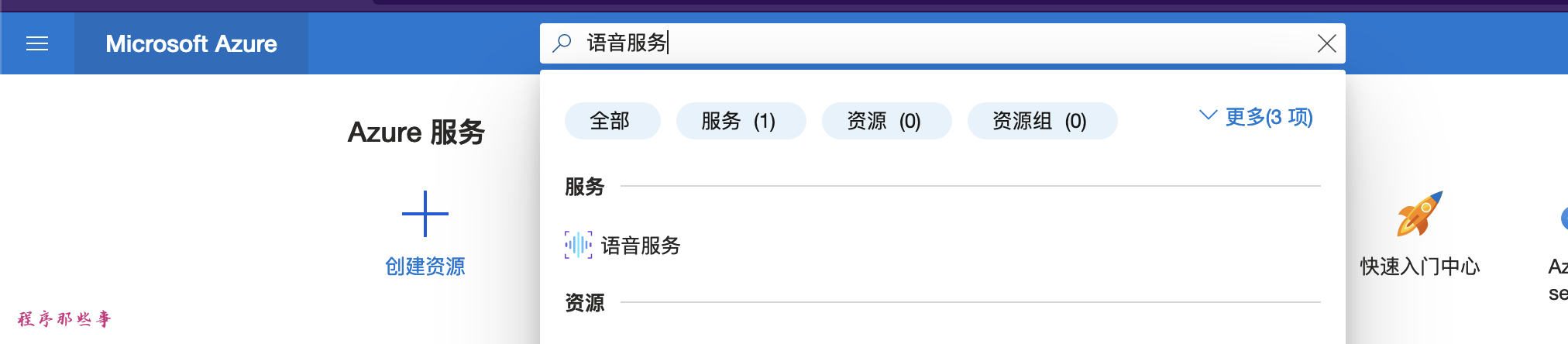
点击下面的语音服务,进入到Azure的语音服务页面。
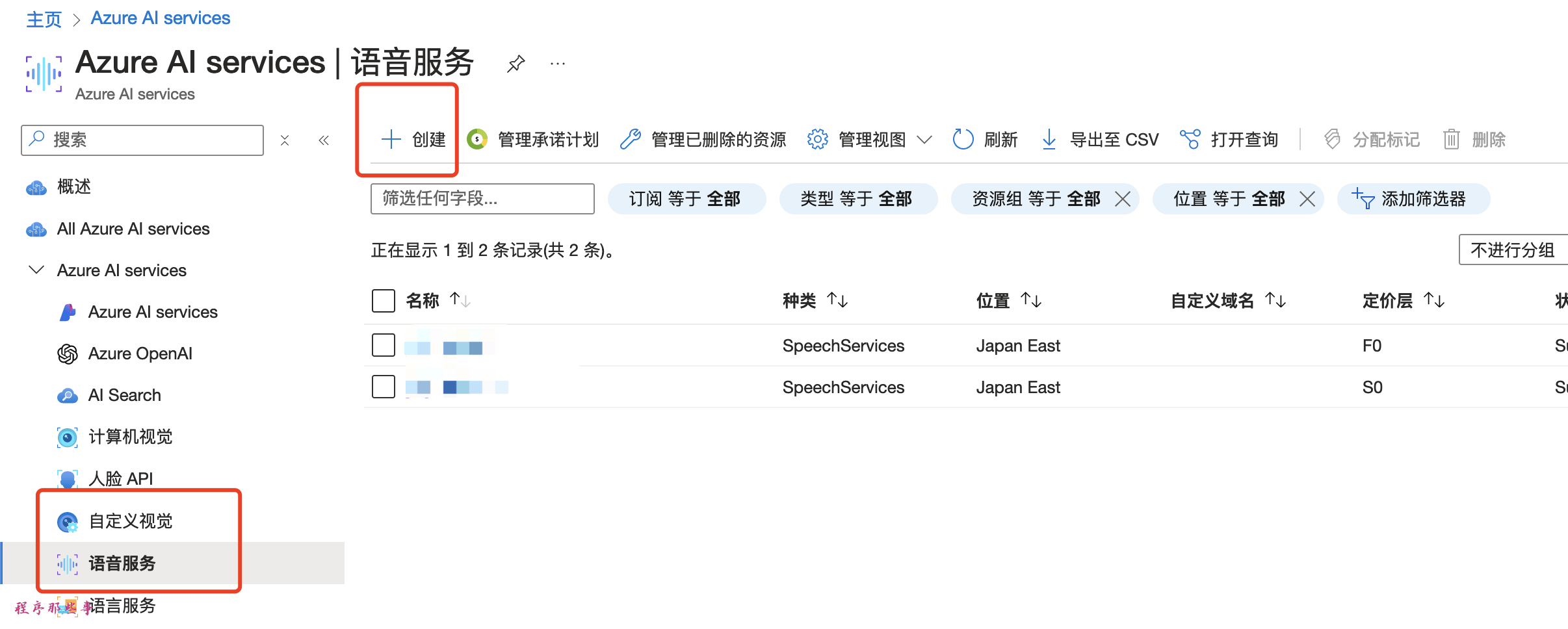
到语音服务这里,点击创建按钮,会进入创建语音服务页面:
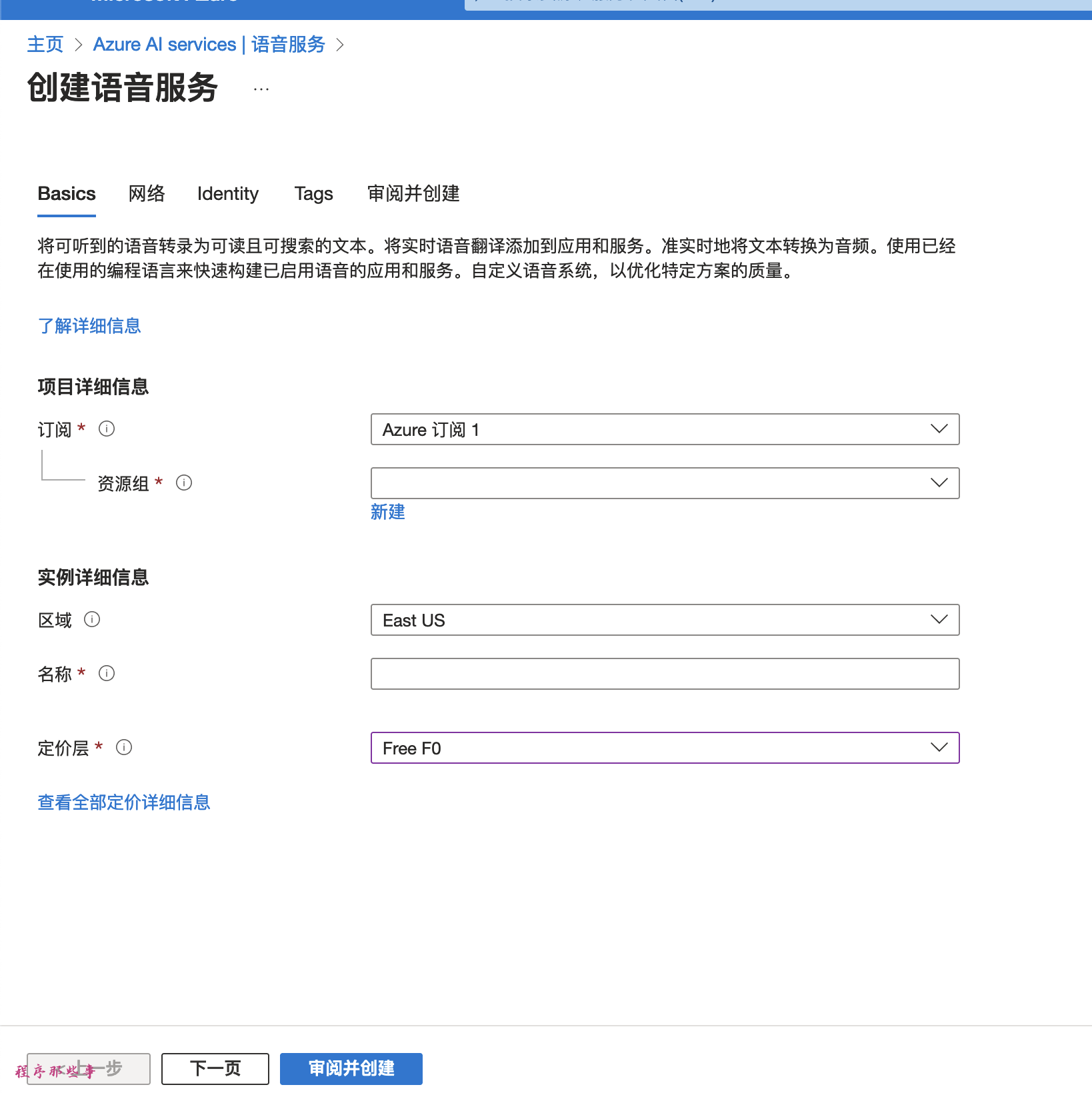
填上必须的内容。点击审阅并创建,就可以创建好Azure的服务了。
记住你的密钥和region:
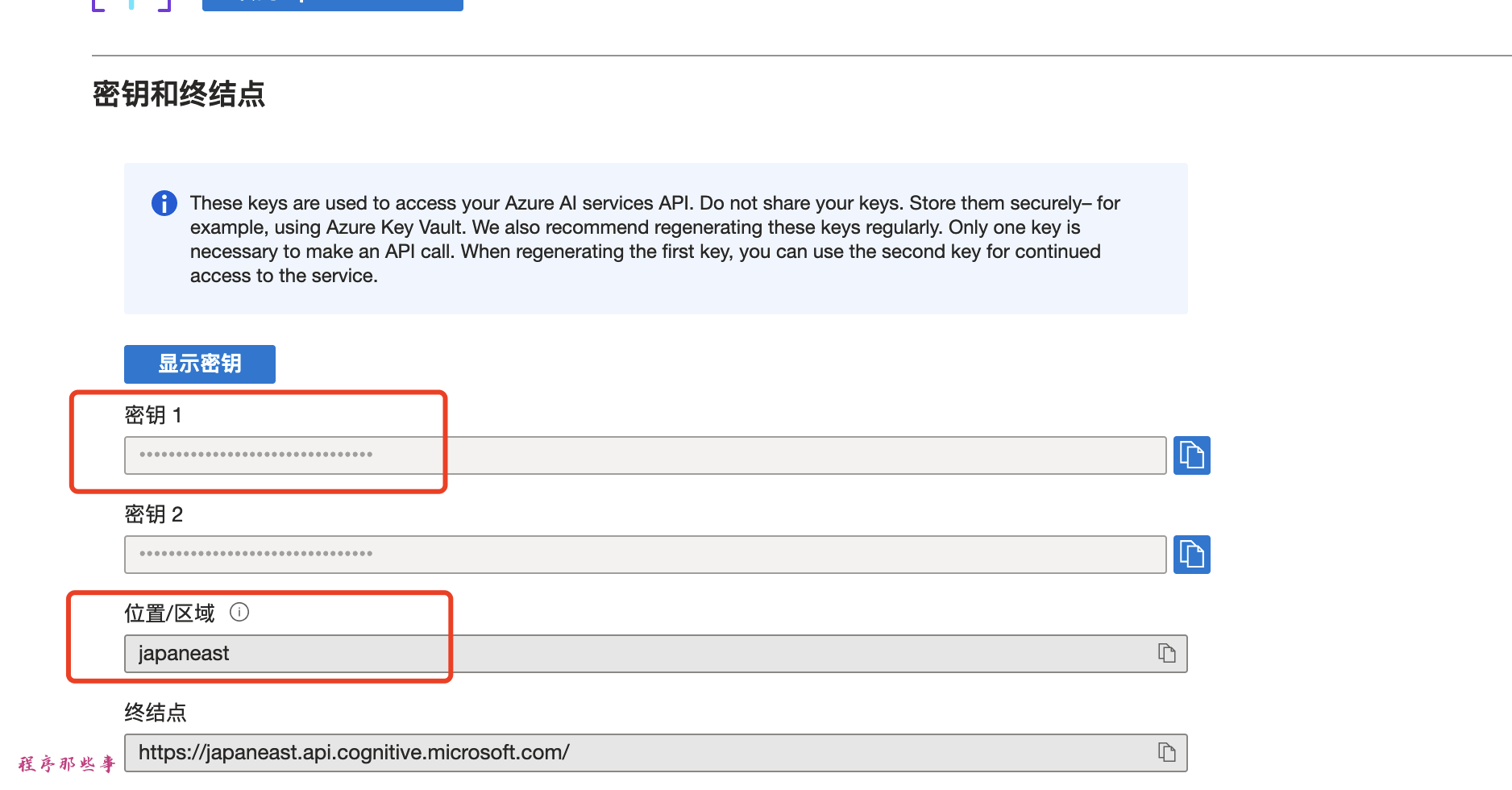
在MoneyPrinterPlus中配置
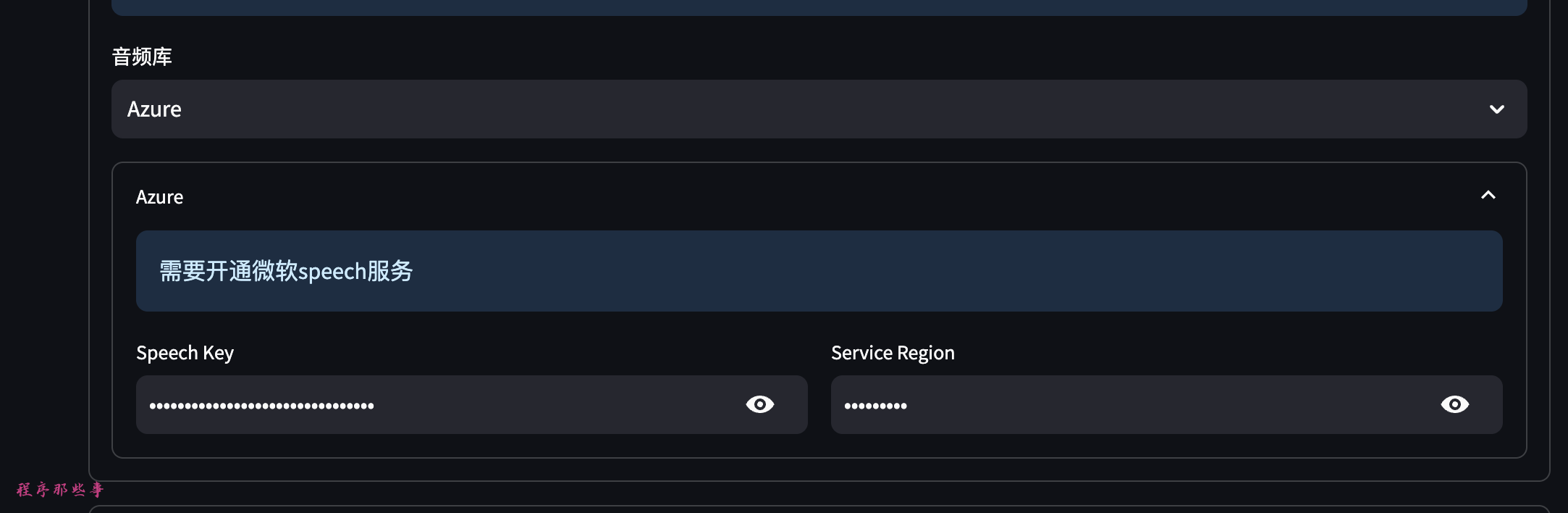
启动我们的项目,在web页面点击最左边的基础配置,找到右边的配置音频库信息,选择Tencent。
填入我们之前保存的密钥和region。
回车后,这样我们的配置就保存了。
其��他的配置
资源库
资源库指的是我们从哪里获取视频或者图片信息,这里目前提供了两个资源提供方,分别是pexels和pixabay。
大家任意选择一个即可。
以pexels为例,我们登入pexels官网 https://www.pexels.com/zh-cn/ ,注册一个账号。
在图片和视频API里面,可以查看自己的api密钥。
查看自己的API密钥:
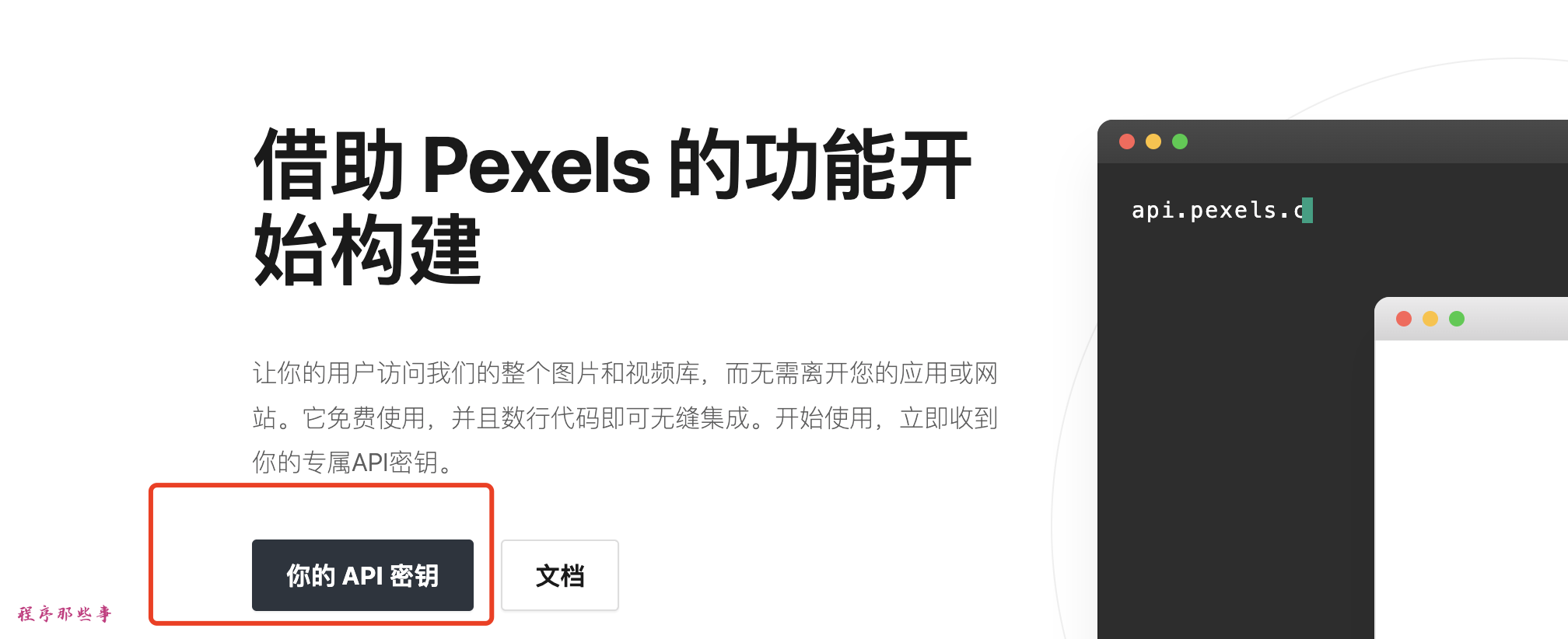
把这个API密钥记下来,拷贝到MoneyPrinterPlus的配置即可。

大模型配置
目前支持Moonshot,openAI,Azure openAI,Baidu Qianfan, Baichuan,Tongyi Qwen, DeepSeek这些。
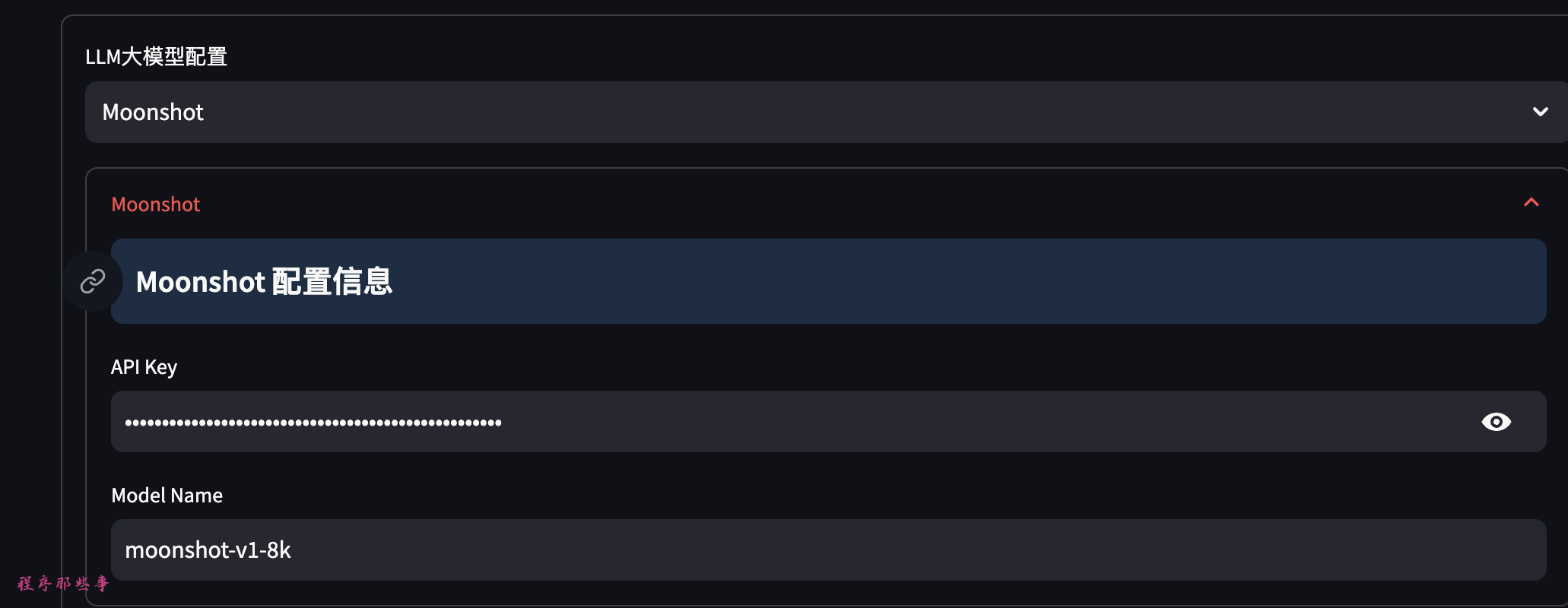
国内要用的话推荐Moonshot(最近发现moonshot不太稳定,大家可以考虑Baichuan或者DeepSeek)。
同样的到Moonshot开发者平台上注册一个key:https://platform.moonshot.cn/ 填入对应的配置即��可。
AI短视频生成
有了基础配置之后,就可以点击左边的AI视频进入AI视频生成页面。
- LLM视频文案生成
在视频主题区输入你需要生成的视频主题,然后点击生成视频文案。
程序会自动使用大模型生成对应的视频文案和视频文案关键字:
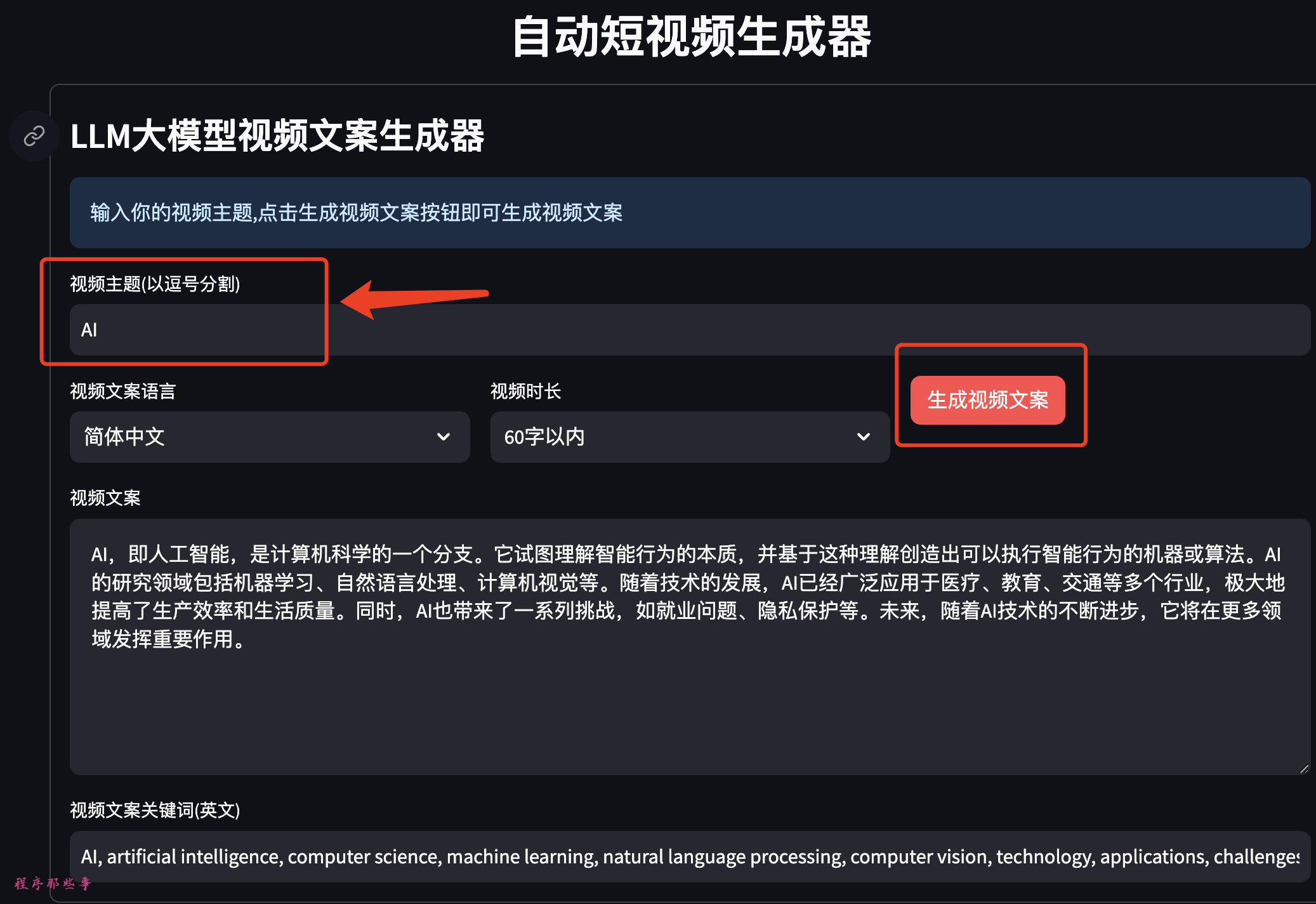
如果你对视频文案或者关键字不满意,可以手动进行修改。
- 视频配音区
在视频配音区可以选择配音语言和对应的配音语言,目前支持100+配音语言。
还可以选择不同的配音语速,以支持不同使用场景。

如果你对配音不太确定,可以点击试听声音试听对应的配音语音。
- 背景音乐
背景音乐放在项目下的bgmusic目录下面,你可以自行添加背景音乐文件到该文件夹下面。

可以选择是否开启背景音乐,和默认的背景音乐音量。
- 视频配置区
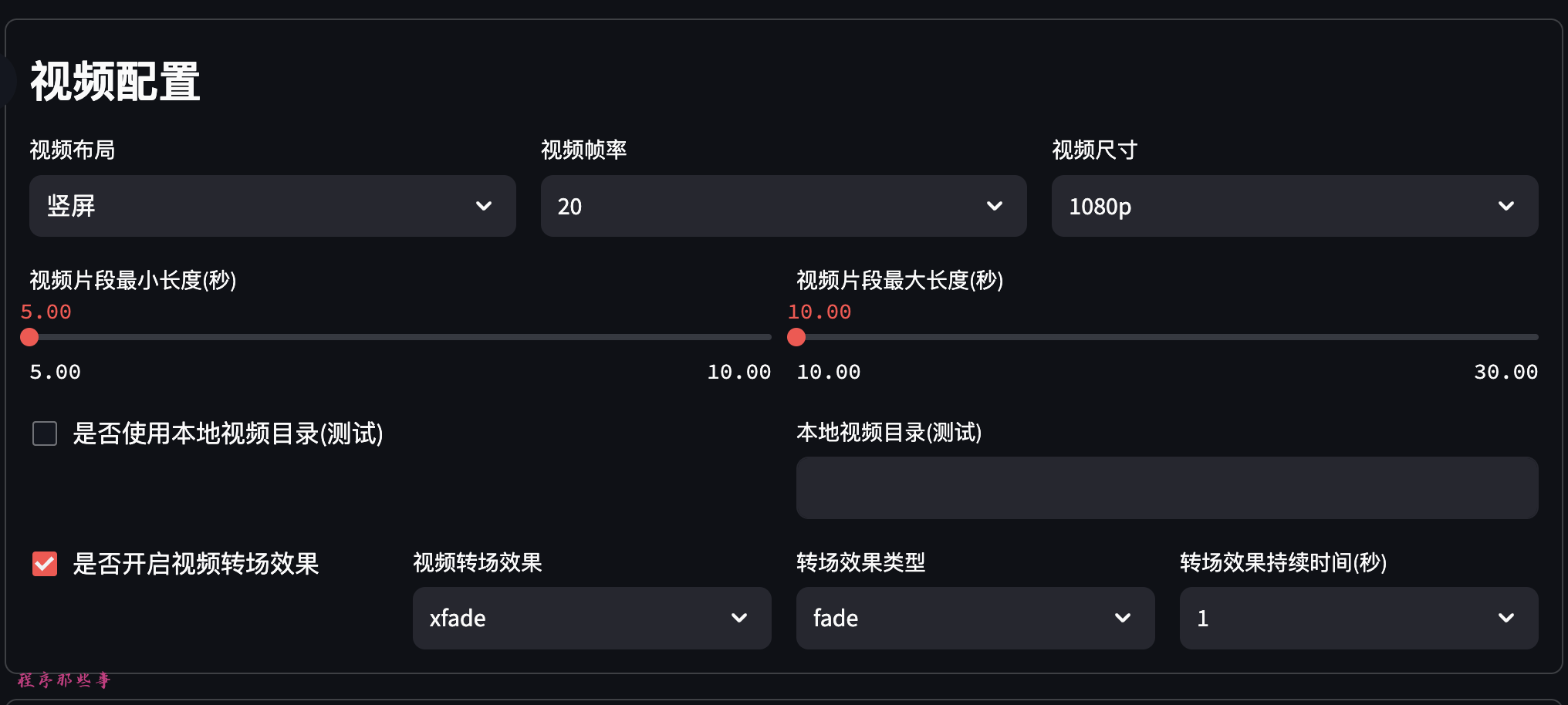
视频配置区可以选择视频布局:竖屏,横屏或者方形。
可以选择视频帧率,视频的尺寸。
还可以选择每个视频片段的最小长度和最大长度。
最最重要的,还可以开启视频转场特效。目前支持30+视频转场特效。
- 字幕配置
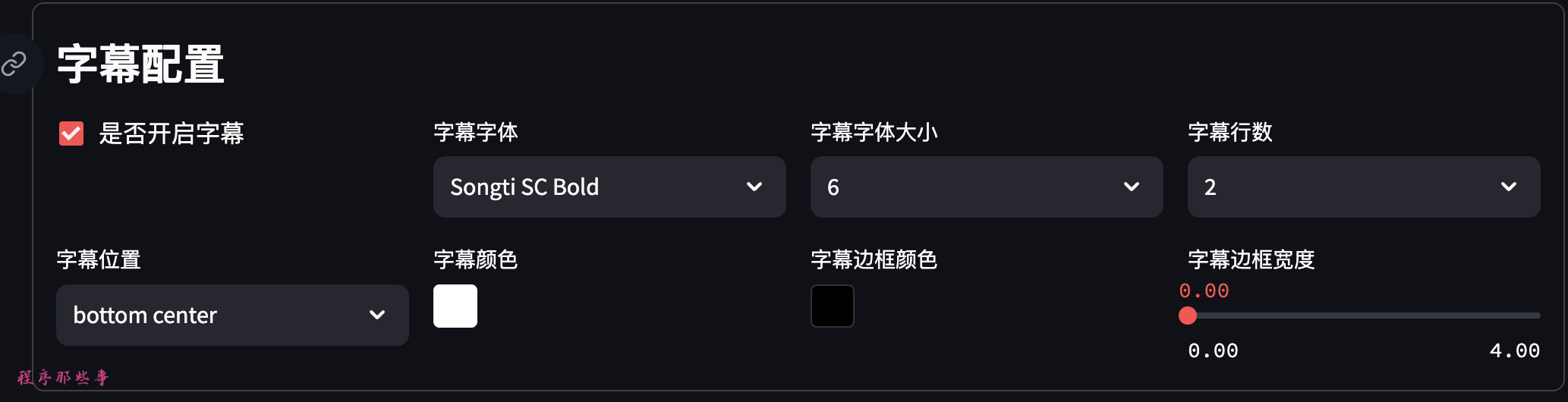
如果你需要字幕,那么可以点击开启字幕选项,可以设置字幕字体,字幕字体的大小和字幕颜色等。
如果你不知道怎么设置,选择默认即可。
- 最后的视频生成
最后点击生成视频按钮即可生成视频。
页面会有相应的进度提醒。
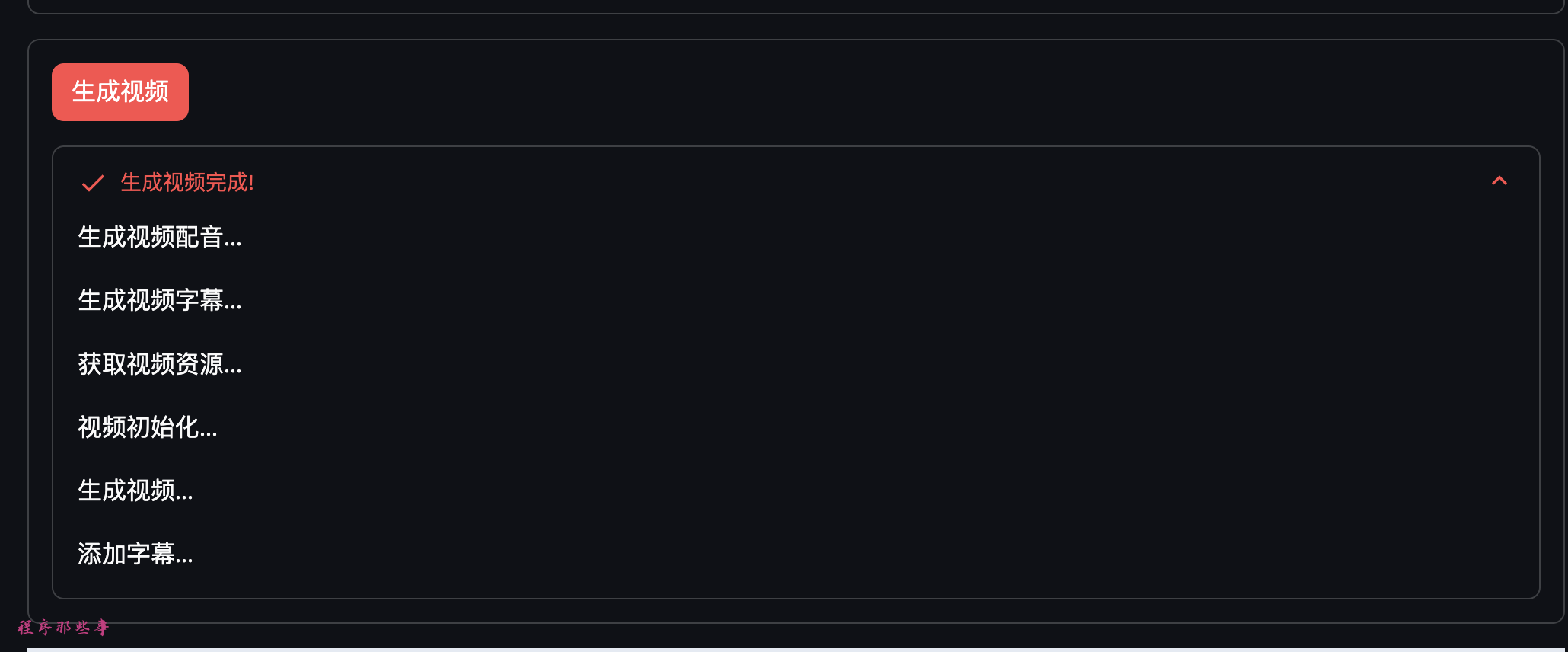
最后生成的视频会展示在页面最下面,大家可以自行播放。