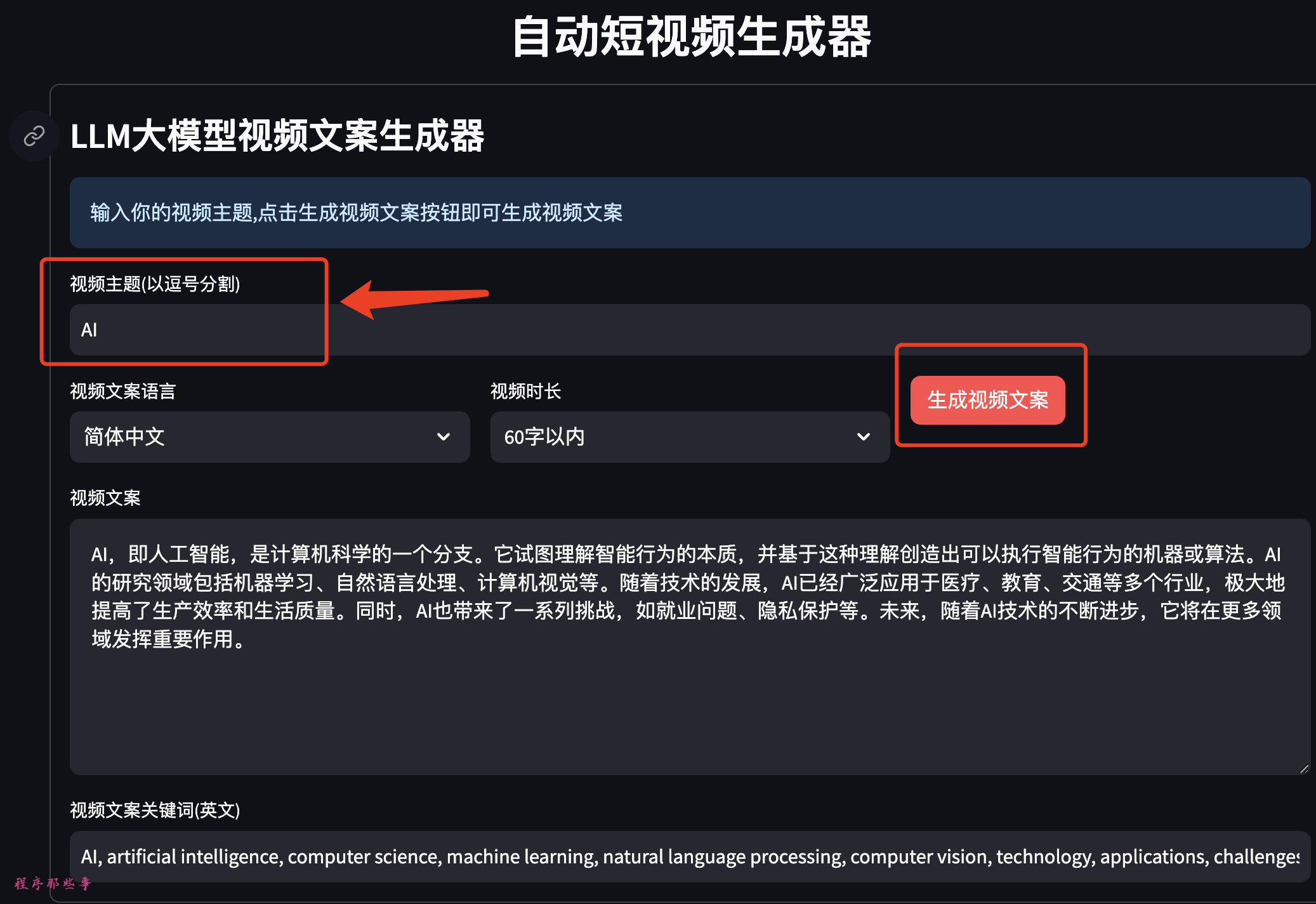
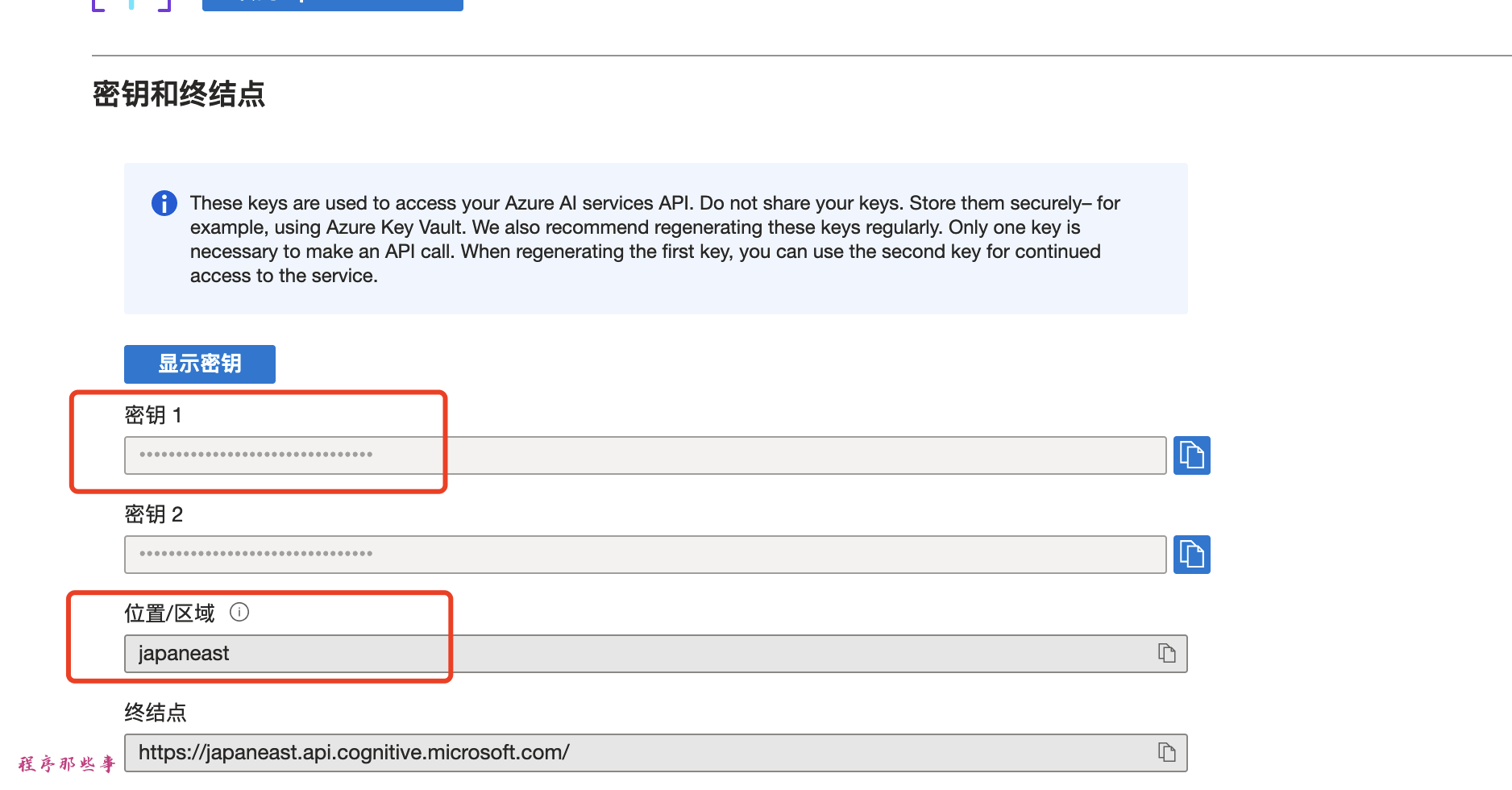
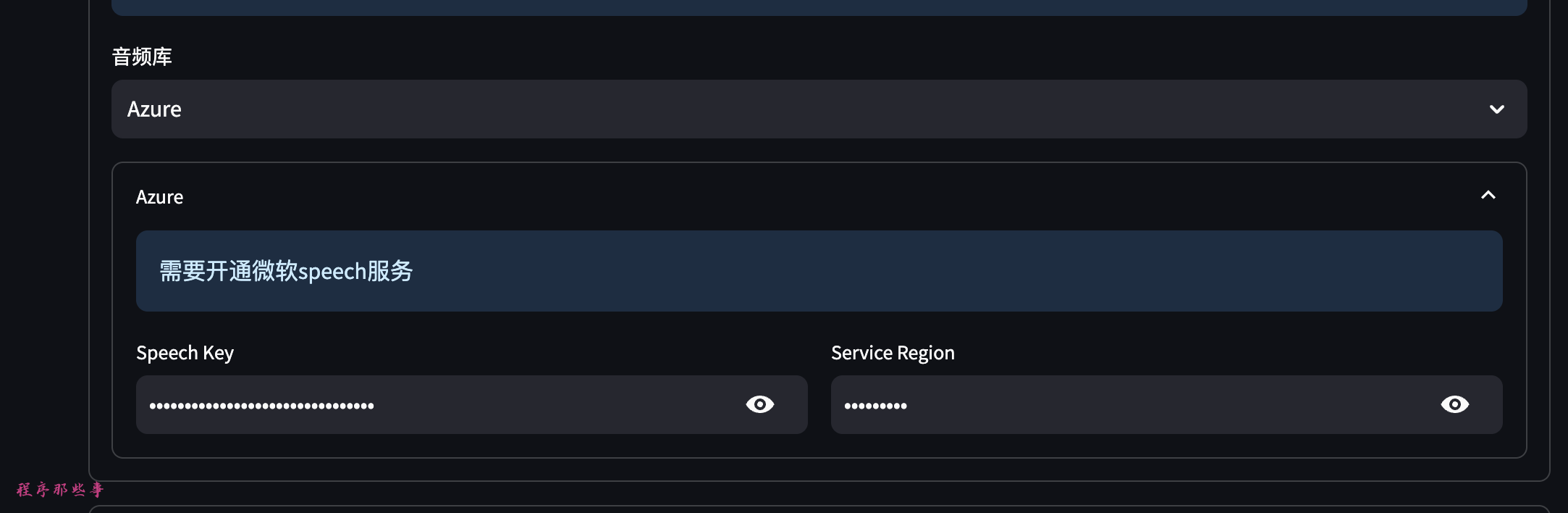
最近有很多优秀的语�音合成TTS工具,目前MoneyPrinterPlus已经集成了ChatTTS和fasterWhisper。应朋友们的要求,最近MoneyPrinterPlus也集成了GPT_SoVITS这个优秀的语音合成工具。
今天给大家详细讲解一下,如何在MoneyPrinterPlus中使用GPT_SoVITS。
软件准备
当然,前提条件就是你需要下载MoneyPrinterPlus软件啦。
下载地址: https://github.com/ddean2009/MoneyPrinterPlus
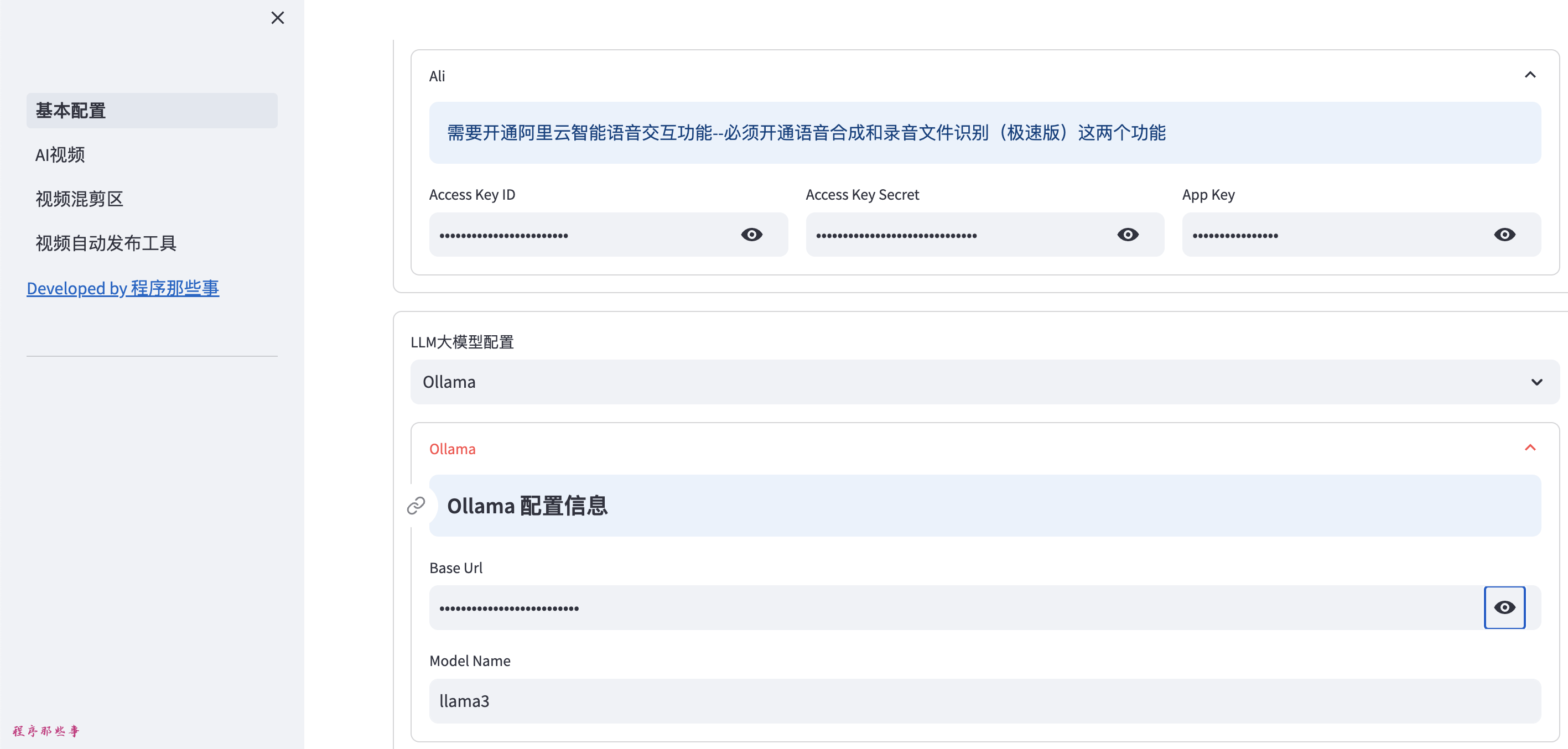
用得好的朋友,不妨给个star支持一下。 在软件v4.4版本之后,MoneyPrinterPlus已经支持GPT_SoVITS本地TTS语音服务啦。
启动GPT_SoVITS
GPT_SoVITS这个工具怎么安装这里就不多讲了。
我们讲下如何跟MoneyPrinterPlus进行合作配置。
GPT_SoVITS有很多功能,包括语音训练,模型微调,TTS语音推理,变声等功能。
这里我们使用的是GPT_SoVITS的核心TTS语音推理功能。
首先我们启动GPT_SoVITS:
在1-GPT-SoVITS-TTS ---》 1C推理 ---》 开启TTS推理webUI
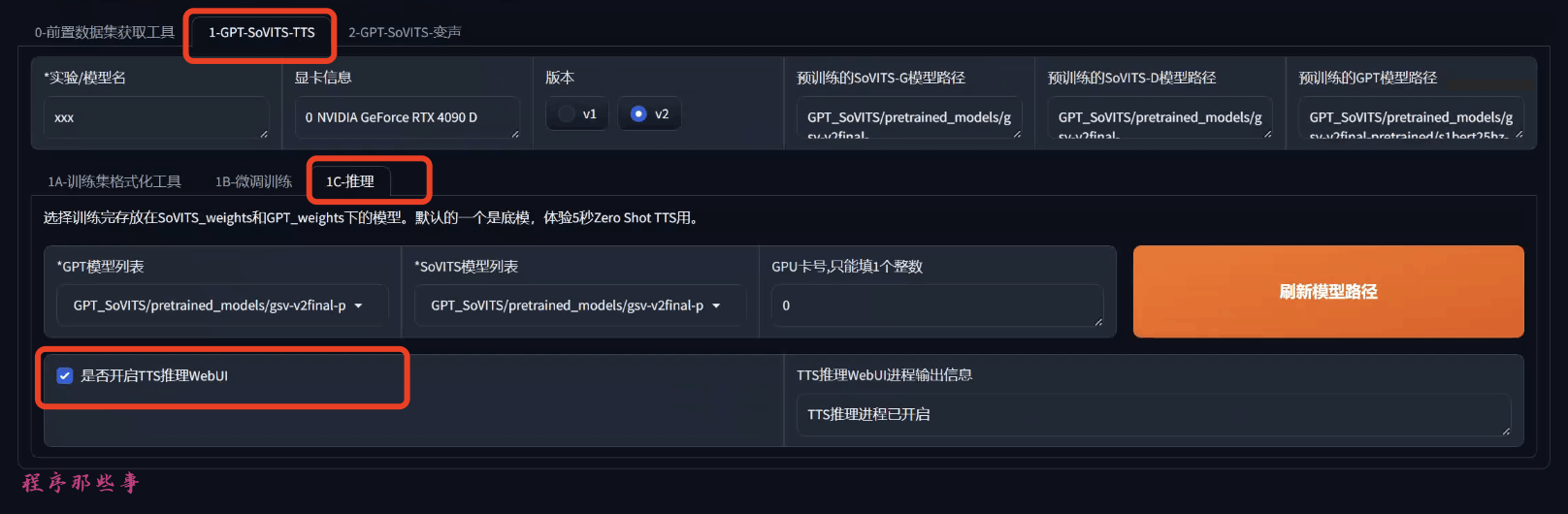
然后你就可以看到这样的TTS推理界面:
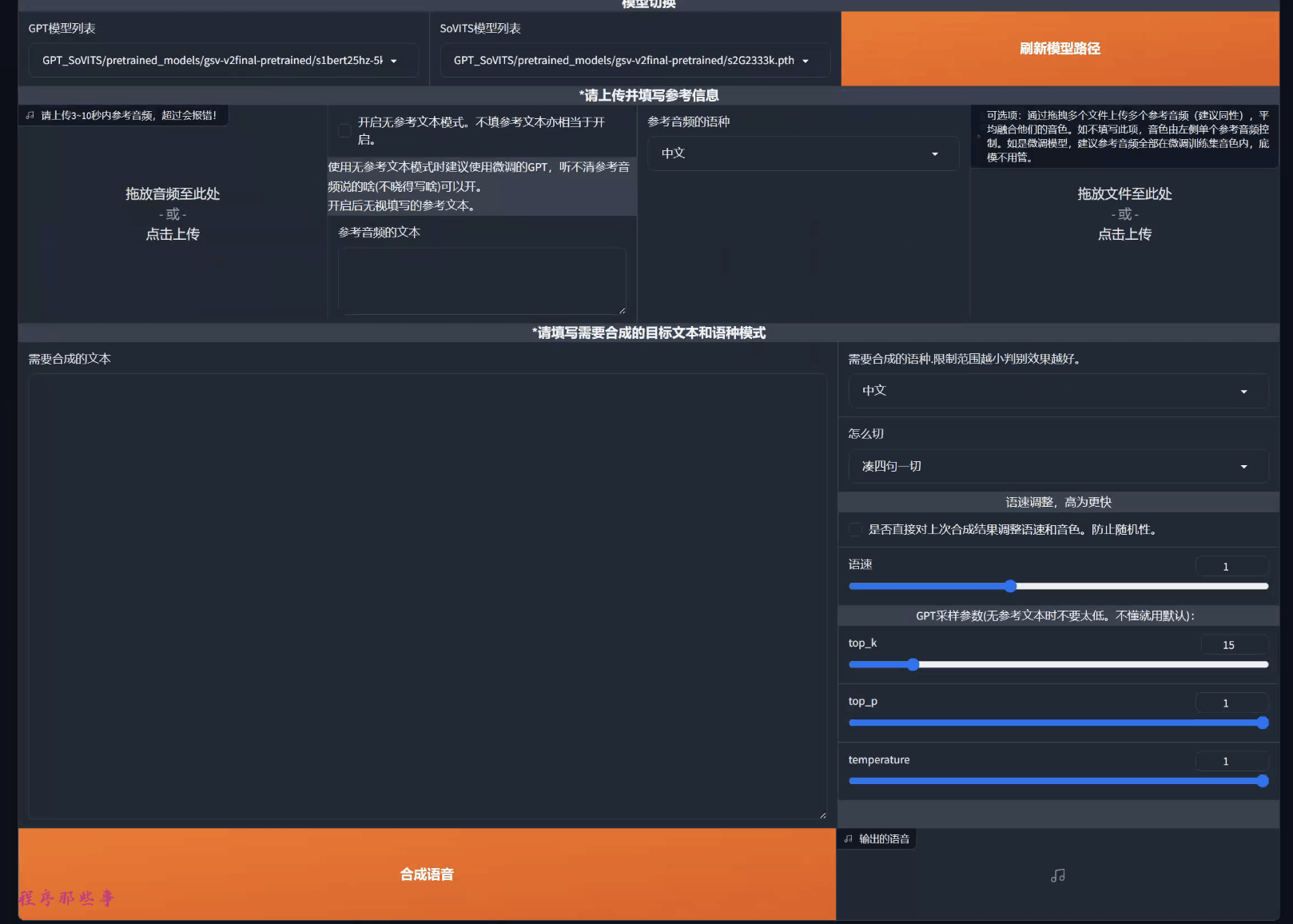
你可以选择参考音频,参考文本,参考音频的语言。
然后可以输入要合成的文本,合成语音的类别,语速,top_k, top_p和temperature。
当然,上面的都不重要,我们不需要通过webUI来调用GPT_SoVITS,我们需要的是通过API来和GPT_SoVITS进行交互。
API启动GPT_SoVITS
如果下载的是GPT_SoVITS的集合包,那么可以直接执行下面的命令来启动GPT_SoVITS的API:
启动api: runtime\python.exe api.py
启动之后,你会看到下面的内容:
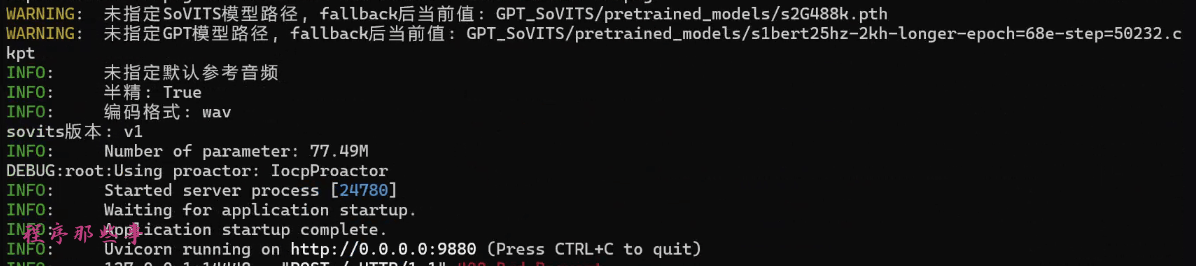
上面的启动是最简单的启动,没有指定参考音频,如果你想指定参考音频的话,可以执行下面的命令:
python api.py -dr "123.wav" -dt "一二三。" -dl "zh"
当然,还有其他的一些启动参数如下:
`-dr` - `默认参考音频路径`
`-dt` - `默认参考音频文本`
`-dl` - `默认参考音频语种, "中文","英文","日文","韩文","粤语,"zh","en","ja","ko","yue"`
`-d` - `推理设备, "cuda","cpu"`
`-a` - `绑定地址, 默认"127.0.0.1"`
`-p` - `绑定端口, 默认9880, 可在 config.py 中指定`
`-fp` - `覆盖 config.py 使用全精度`
`-hp` - `覆��盖 config.py 使用半精度`
`-sm` - `流式返回模式, 默认不启用, "close","c", "normal","n", "keepalive","k"`
·-mt` - `返回的音频编码格式, 流式默认ogg, 非流式默认wav, "wav", "ogg", "aac"`
·-cp` - `文本切分符号设定, 默认为空, 以",.,。"字符串的方式传入`
`-hb` - `cnhubert路径`
`-b` - `bert路径`
大家可以根据需要自行选择。
默认情况下API会启动在9880端口,我们可以使用下面的命令来测试API的启动效果:
使用执行参数指定的参考音频:
GET:
`http://127.0.0.1:9880?text=先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。&text_language=zh`
POST:
```json
{
"text": "先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。",
"text_language": "zh"
}
```
配置MoneyPrinterPlus
好了,回到我们的MoneyPrinterPlus页面。
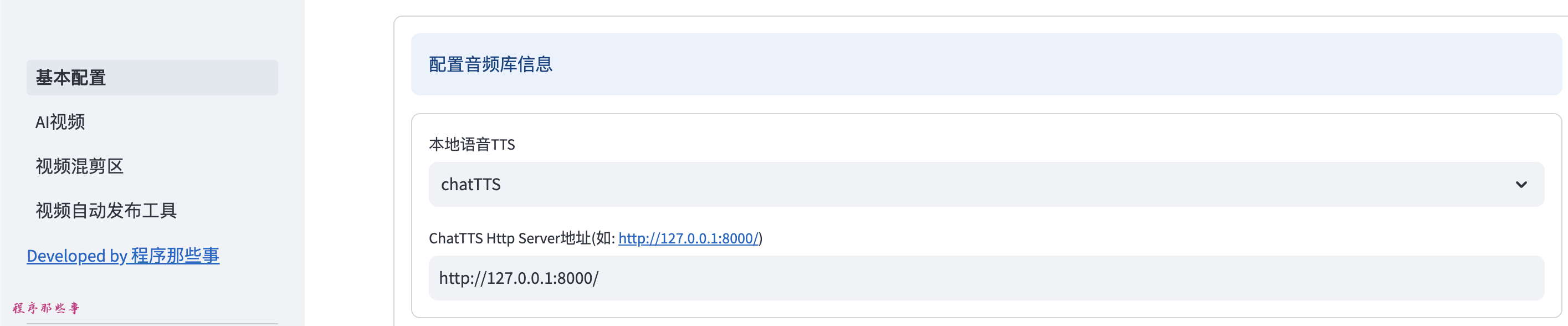
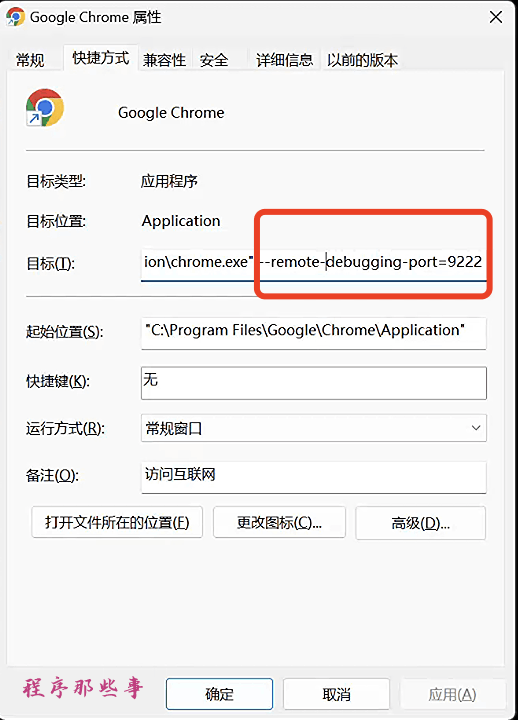
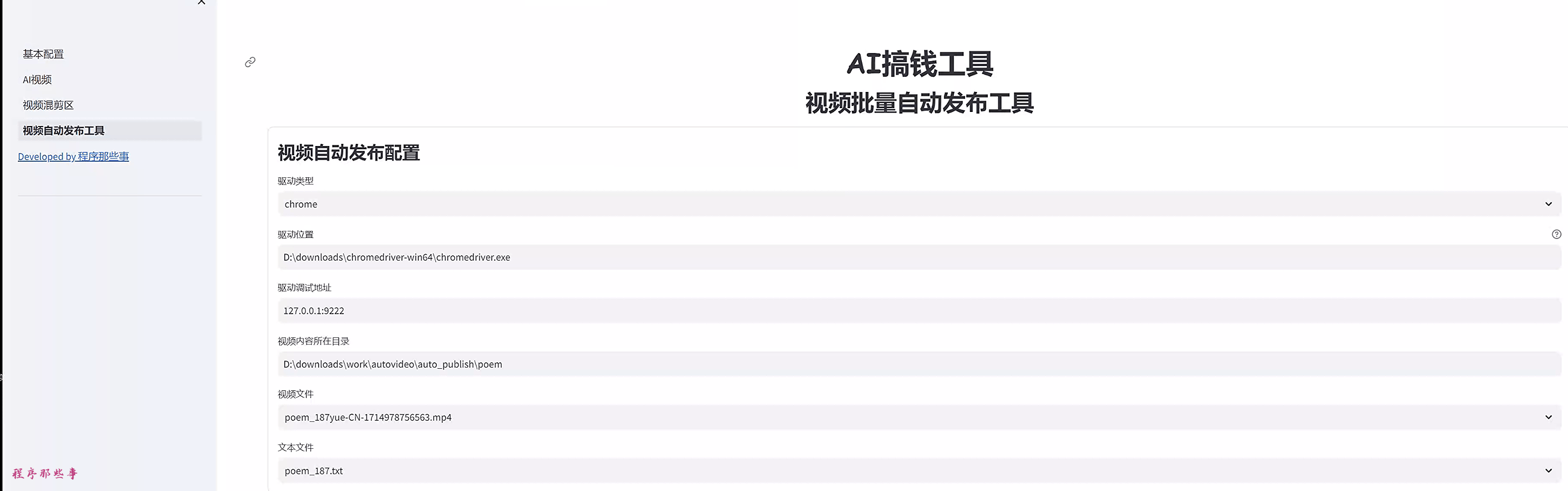
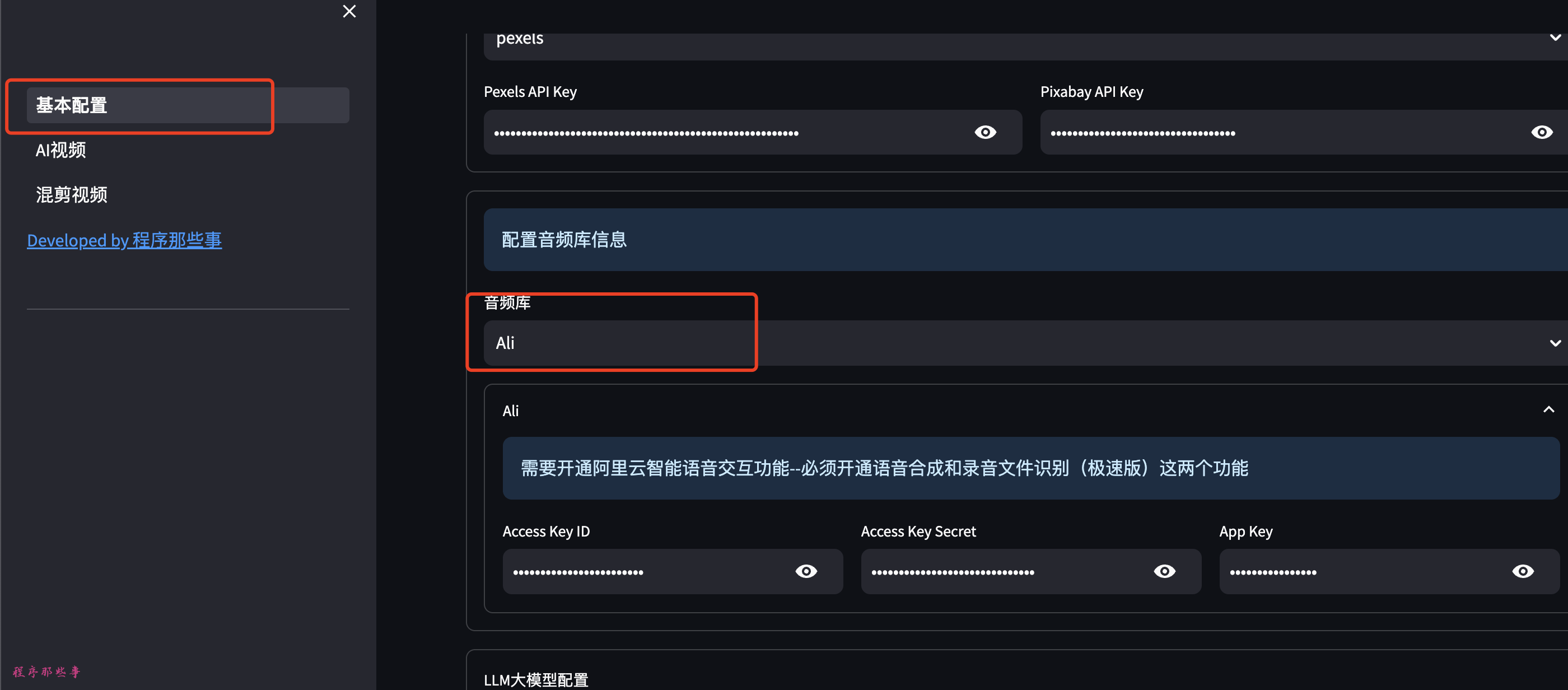
在基本配置页面,本地语音TTS,我们选择GPTSoVITS, 然后输入GPTSoVITS的地址。

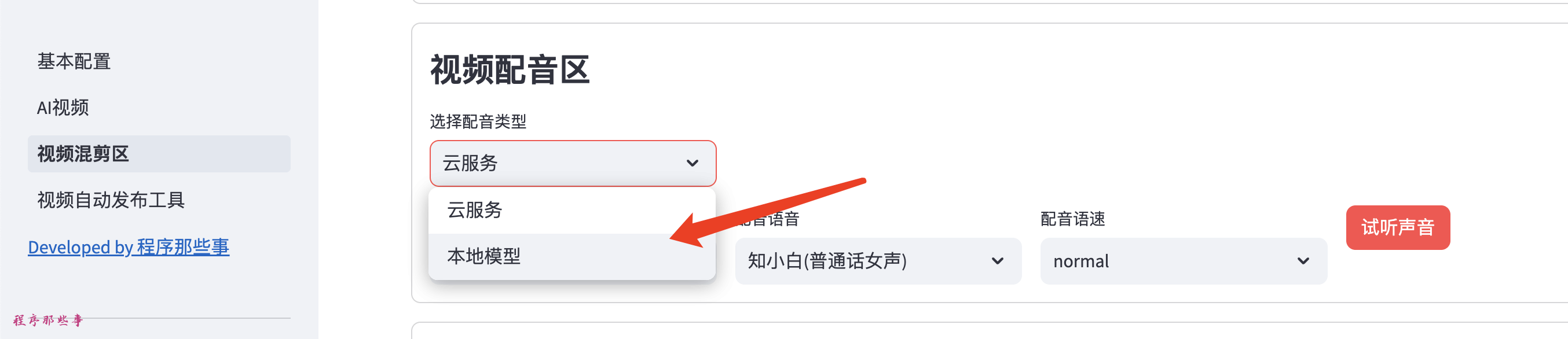
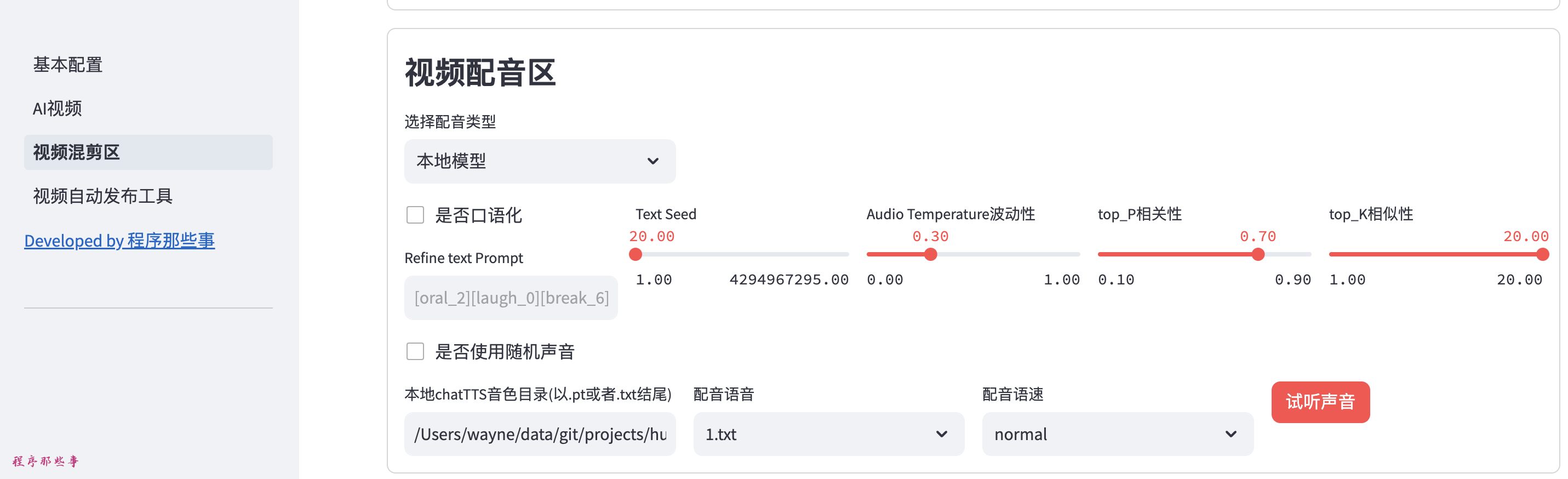
在AI视频或者视频混剪区,在视频TTS语音合成区,我们选择本地服务。
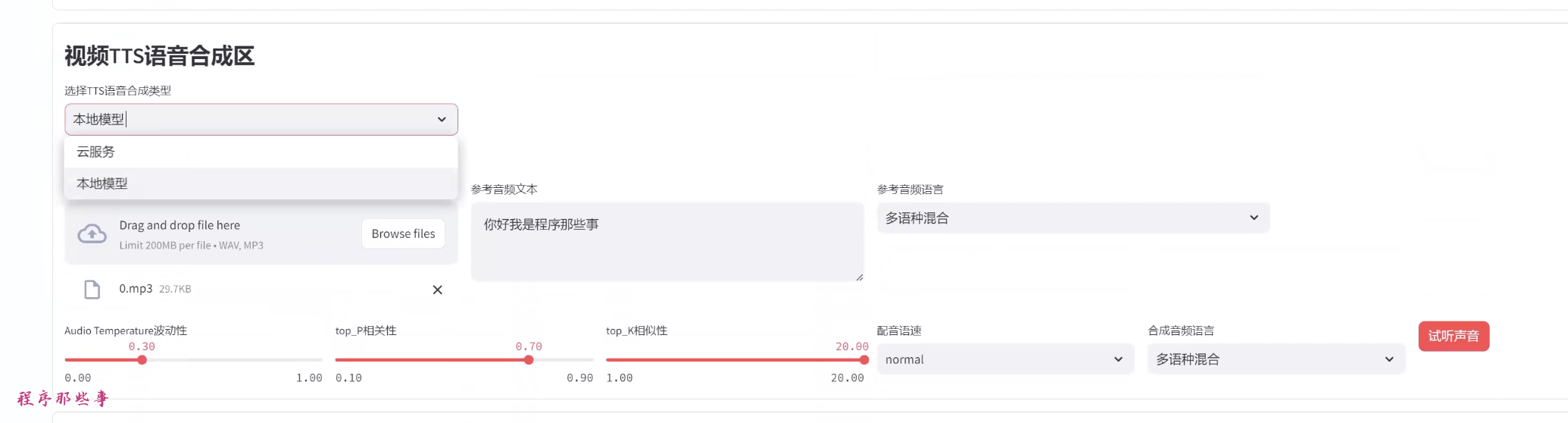
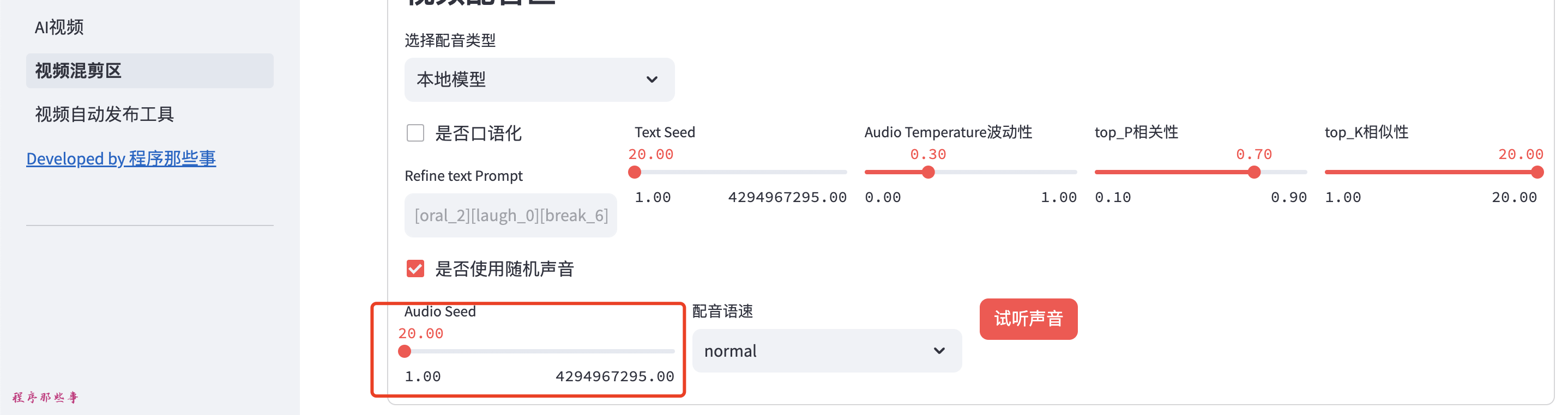
这里列出来GPTsoVITS所需要的大部分参数。
你可以使用参考音频,参考音频文本,参考音频语音。
然后可以条件temperature,top_P, top_K等信息。
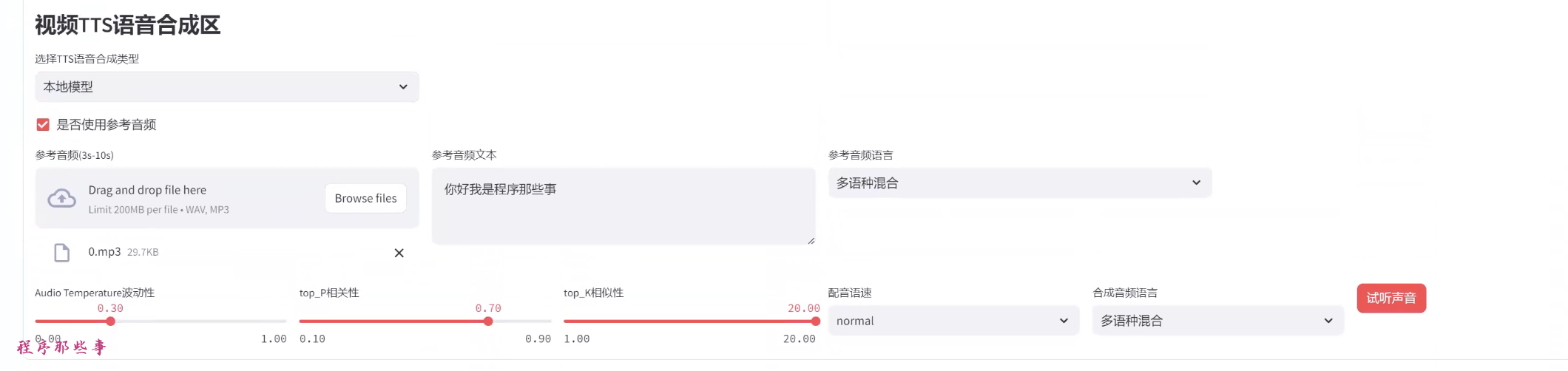
点击试听声音,如果你听到合成的声音,那么恭喜你,你的配置成功了。
同时,在GPTsoVITS服务的日志文件中,你可以看到一些语音合成的进度。
总结
GPTsoVITS是一个非常强大的服务,和MoneyPrinterPlus结合起来使用,你将会无往不利。