之前MoneyPrinterPlus在批量混剪,一键AI生成视频这些功能上的语音合成功能都用的是云厂商的语音服务,比阿里云,腾讯云和微软云。
云厂商虽然提供了优质的语音服务,但是用起来还是要收费。
为了各位小伙伴的钱包,现在特意给MoneyPrinterPlus上线了本地chatTTS语音服务。
赶紧来体验吧。
软件准备
当然,前提条件就是你需要下载MoneyPrinterPlus软件啦。
下载地址: https://github.com/ddean2009/MoneyPrinterPlus
用得好的朋友,不妨给个star支持一下。 在软件v4.0版本之后,MoneyPrinterPlus已经全面开始支持本地模型。
安装chatTTS
我们可以直接从chatTTS的官网上 https://github.com/2noise/ChatTTS 下载chatTTS的源代码:
git clone https://github.com/2noise/ChatTTS
cd ChatTTS
安装依赖:
pip install --upgrade -r requirements.txt
运行web-UI:
python examples/web/webui.py
运行api-server:
fastapi dev examples/api/main.py --host 0.0.0.0 --port 8000
这里注意,web-ui的默认端口是8080, api-server的端口是8000。
MoneyPrinterPlus需要连接的是8000端口的api-server。
web-UI只是为了展示怎么配置音色的一个展示用的。
我们打开 http://localhost:8080/ 可以看到类似下面的页面:
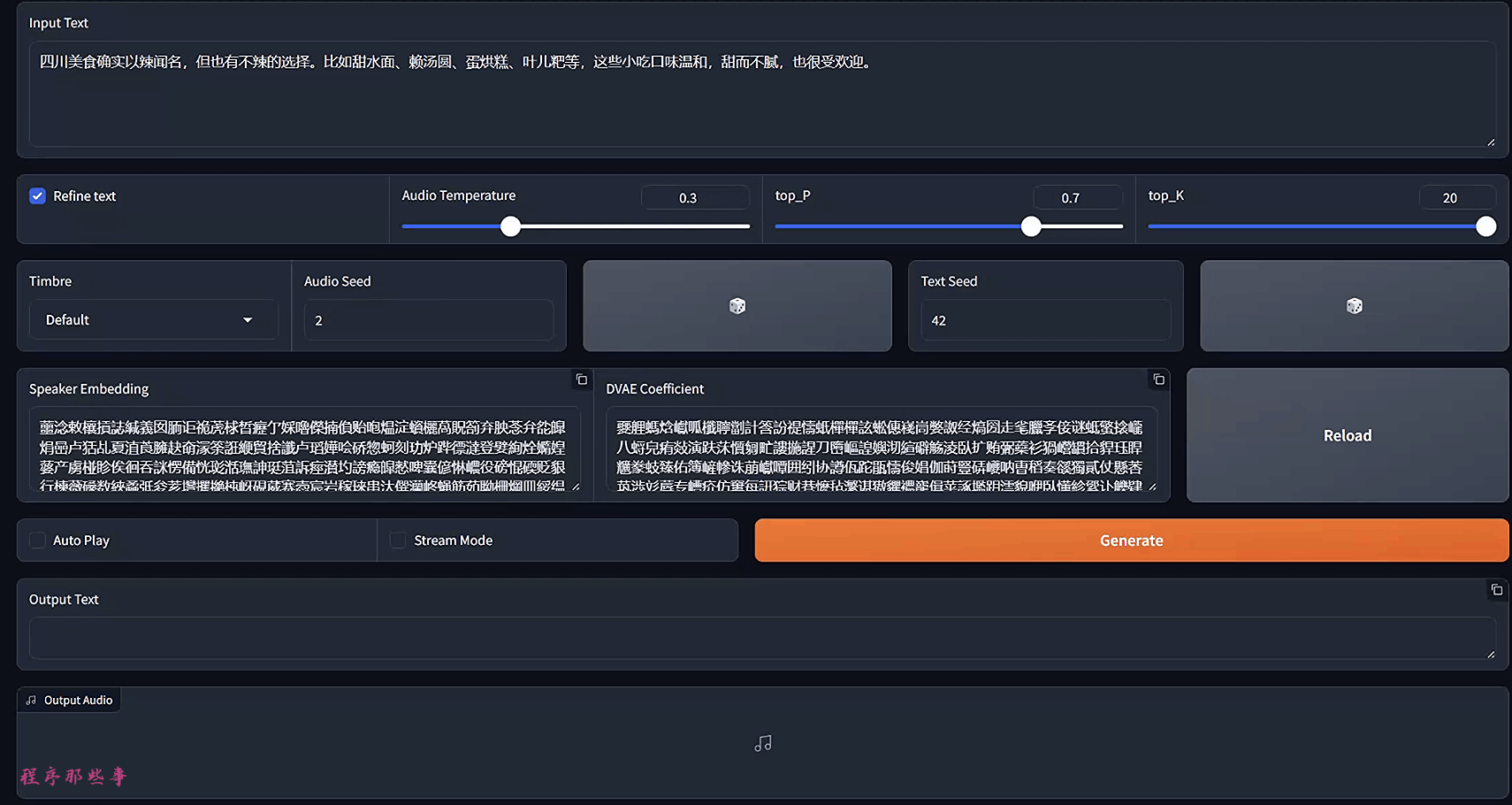
点击生成按钮,如果能够成功合成音频文件,那么说明你的chatTTS安装成功了。
在MoneyPrinterPlus中使用ChatTTS
回到MoneyPrinterPlus,我们启动MoneyPrinterPlus,在基本配置页面我们可以看到:本地语音TTS的选项。
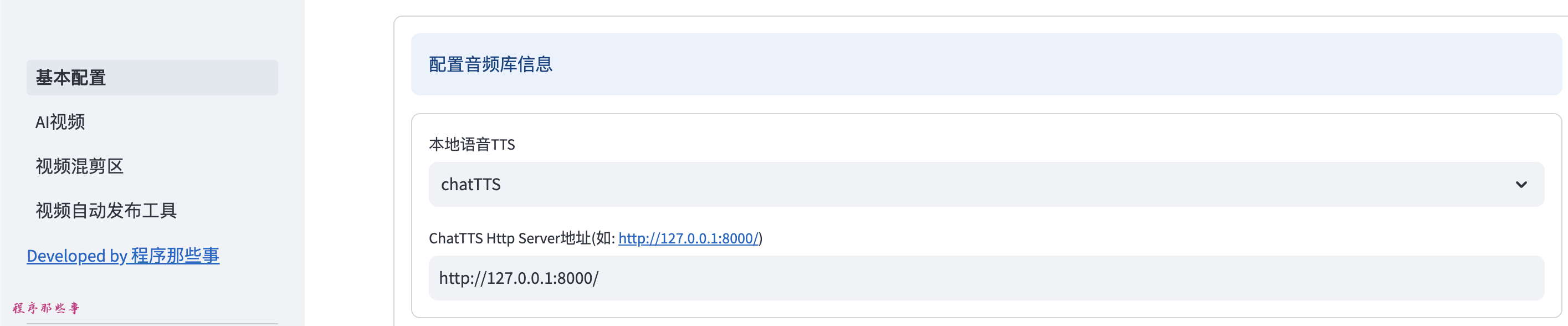
这里我们选择chatTTS,并且设置chatTTS api server的地址。
上面我们是以8000启动的api server,所以这里我们就输入:http://127.0.0.1:8000/。
接下来点击视频混剪区,在视频配音区选择本地模型:
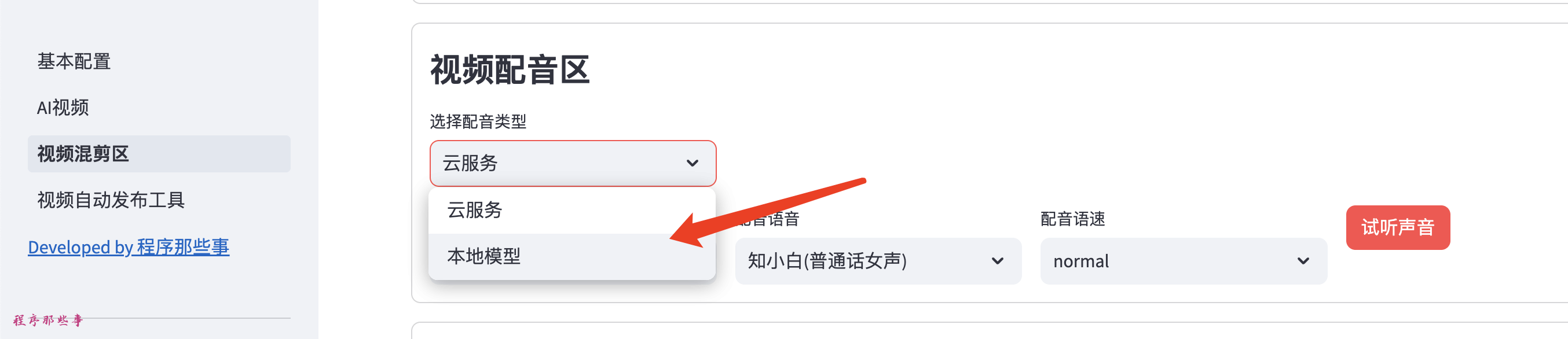
我们可以得到下面的界面:
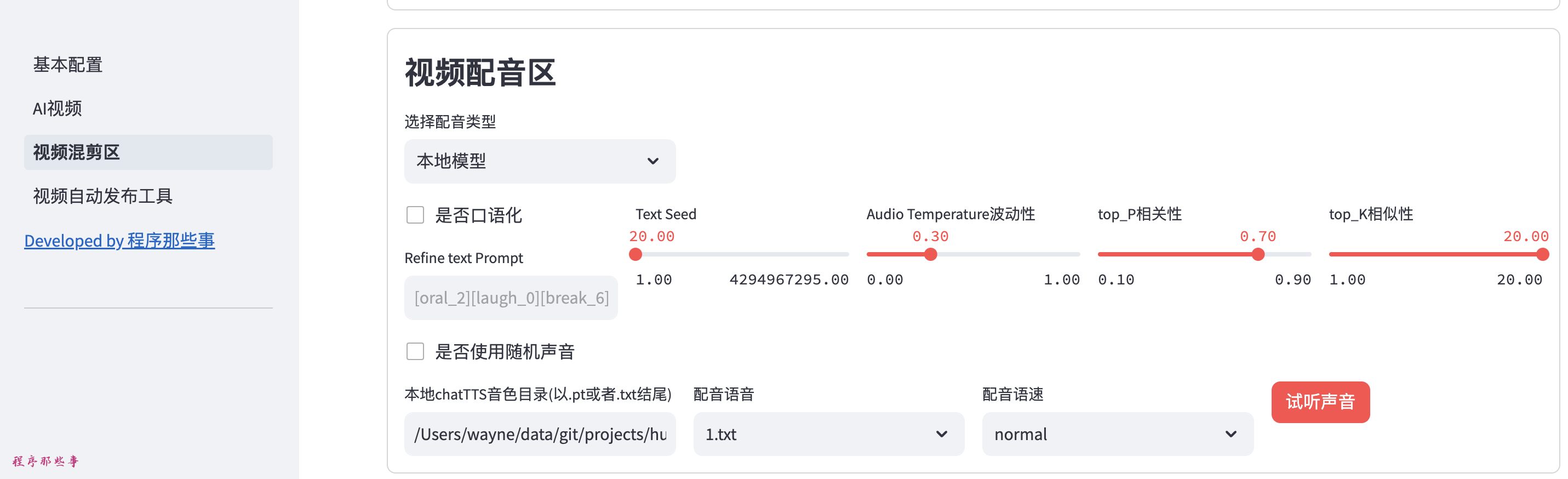
解释一下各个参数的作用:
是否口语化对应chatTTS的口语化开关,如果启动口语化,chatTTS会自动对输入的文案进行口语化调整。所以默认是不开启的。
Text Seed是控制口语化模型处理的种子,你可以随意调整。
Audio Temperature控制音频情感波动性,范围为 0-1,数字越大,波动性越大
top_P :控制音频的情感相关性,范围为 0.1-0.9,数字越大,相关性越高
top_K :控制音频的情感相似性,范围为 1-20,数字越小,相似性越高
Refine text Prompt是指在口语化过程中添加的一些参数。如果不懂的话可以不修改。
本地chatTTS音色目录,默认在项目的chattts目录中。
现在我在chattts目录中预先放置了2种音色文件。
一种是txt文件,一种是pt文件。
你可以自行添加更多的音色文件到chattts目录中。
那么有小伙伴要问了,txt或者pt文件是怎么来的呢?
先讲一个简单的pt文件,你可以在 https://modelscope.cn/studios/ttwwwaa/ChatTTS_Speaker 这个空间中试听和下载对应的语音文件:
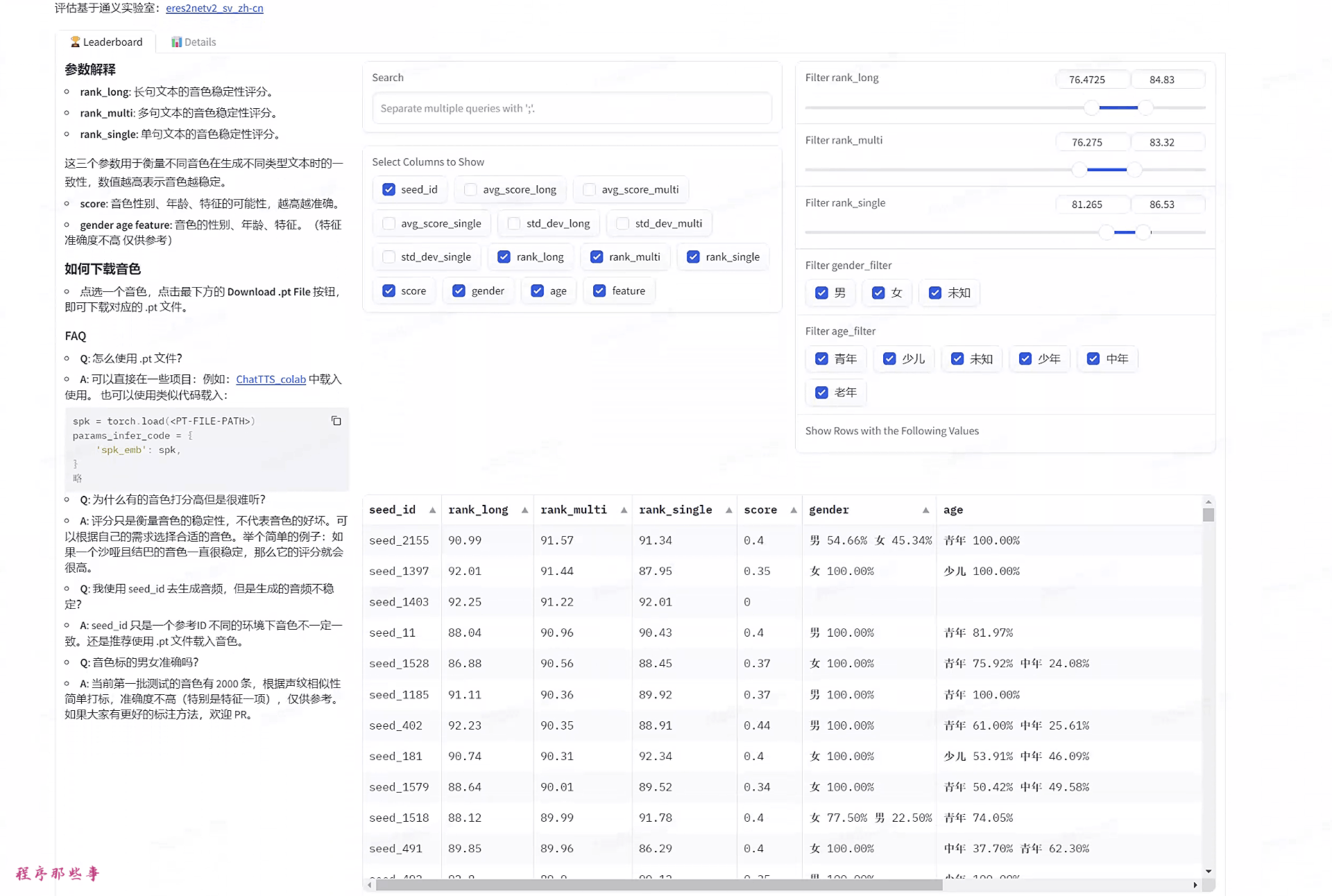
把下载下来的pt文件,放在MoneyPrinterPlus中的chattts目录即可。
txt文件是怎么来的呢?
我们再次回到chatTTS的webUI界面:
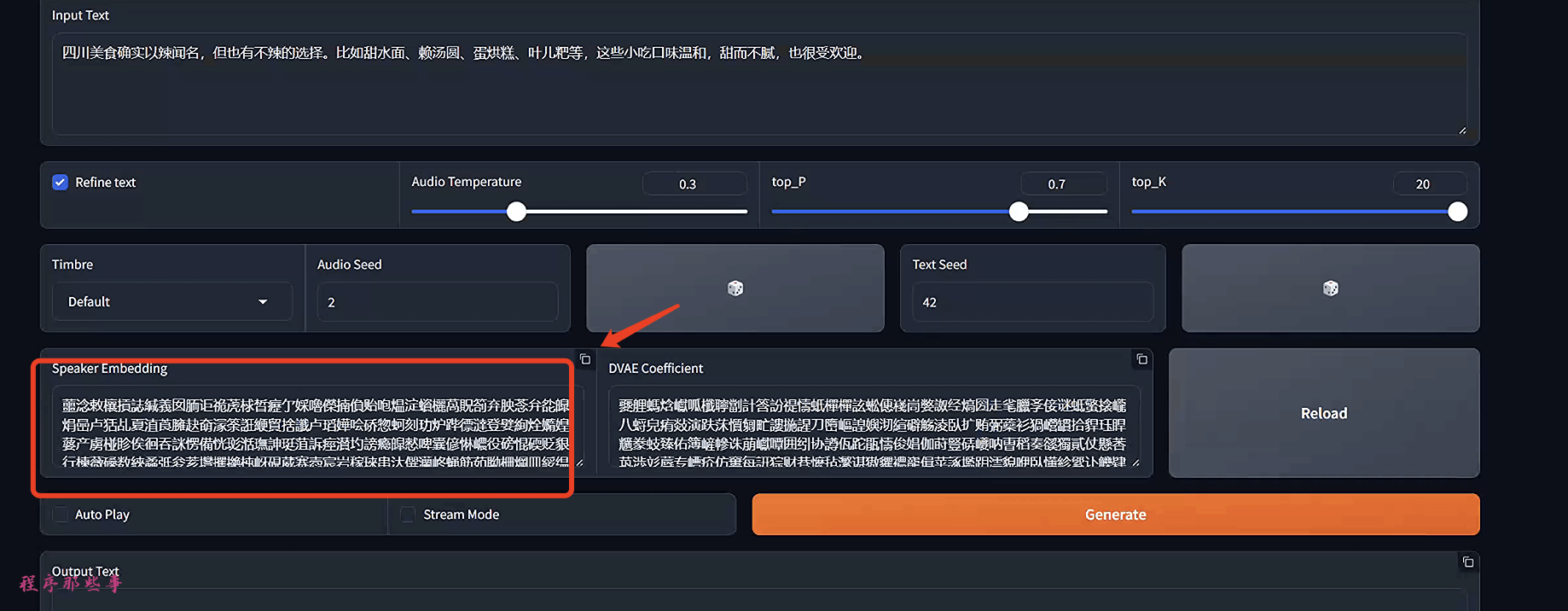
这个txt就是这里的Speaker Embedding的内容。
你可以点击右上角的拷贝按钮,新建一个utf-8编码的txt文件。 把这个txt文件放到MoneyPrinterPlus中的chattts目录即可。
如果你不想用已有的音色文件,那么可以点击使用随机声音按钮:
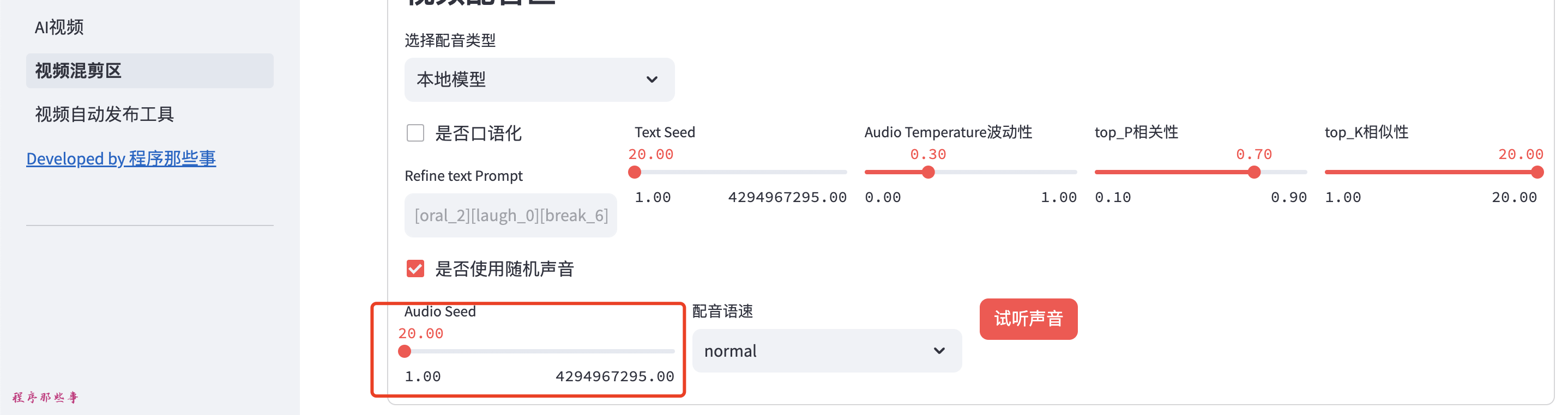
会出现一个Audio Seed选项,这个seed就是用来控制Audio音色的。
有了这些配置之后,点击试听声音,如果能听到声音就说明你的chatTTS在MoneyPrinterPlus中配置成功了。
接下来就可以使用本地的chatTTS来合成语音啦。